
Pointer networks : What are they?
In this article, my aim is to give an explanation of what pointer networks are, as defined in the article “Pointer Networks” (this is the article describing pointers network for the first time I believe), and why they are used. This work is done in the context of my PhD, which is in the field of Natural Language Processing (NLP).
I really write this kind of notes for my own understanding, however, I hope you find that you can benefit from it as well.
I would recommend first reading “Pointer Networks” by Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly, and then coming back here for the explanations that I give.
In the first part of my explanation, I give an overview of what the key terms used in the paper are.
In the second part, I give a summary of the paper.
Clearing out ambiguity
As a general rule, when I am working on learning from a scientific paper, the first step I take is writing down all the unknown or ambiguous terms that are used numerous times in the paper or that seem important for its understanding.
I usually follow these simple steps to find a clear definition:
- With ctrl + f, I find all the occurrences of the ambiguous words in the paper I’m reading. With the context, I generally can start intuiting a definition of the word.
- look up the word on the internet with carefully chosen keywords
Below are some of the unclear terms that I found in the article:
- combinatorial problems:
A combinatorial problem consists in finding, among a finite set of objects, one that satisfies a set of constraints.
In the context of this article, a combinatorial problem is framed as the task of finding for a given input sequence of elements (such as coordinates) and a set of constraints, an output sequence made of tokens, that satisfies constraints.
- tokens:
In this article, tokens are elements of an output sequence, that can be of two kinds: “special” tokens and regular tokens.
> In the case of “special” tokens, they represent the beginning or end of the output sequence.
> A regular token is a list, where an element of the list is one of the indices used to discriminate between the different element of a corresponding input sequence.
For instance, for an input sequence with four elements, there are four indices that go from 1 to 4.
Examples of an output sequence and its corresponding input sequence, extracted from the article:
Cp1={⇒, (1, 2, 4), (1, 4, 5), (1, 3, 5), (1, 2, 3), ⇐} & P1={P_1 , . . . , P_5 }
in the context of the convex hull problem (one of the 3 combinatorial problems presented in the paper).
“⇒” and “⇐” are “special” tokens. Notice how they are placed at both the beginning and end of our output sequence.
“(1, 2, 4)” or “(1, 4, 5)” are regular tokens. They made up of 3 indices that are used to discriminate elements of the input sequence P1={P_1 , . . . , P_5 }.
- output dictionary:
In this context, an output dictionary is a list of all the possible values that a token can take.
Note that in the following example, there is a conflict with the output dictionary:
Cp1={⇒, (1, 2, 8), (1, 4, 5), (1, 3, 5), (1, 2, 3), ⇐} & P1={P_1 , . . . , P_5 }
in the context of the convex hull problem.
Notice how there is no P_8 in our input sequence. This means that the regular token (1, 2, 8) is not in the output dictionary.
Summary of the article
After having read the article a first time and looked for the definitions above, my understanding of the article is the following:
- The focus of this article is on combinatorial problems.
- The aim of the author is to build a model that is able to give a correct output sequence Cp (that respects the constraints defined with the problem), given an input sequence P of variable size.
- Recurrent Neural Network (RNN) based model can only be trained and then used on combinatorial problems with input sequences of the same size.
1. Insights from introduction:

In figure 1, we see a classic sequence to sequence model alongside a Ptr-Net (pointer network) model.
From the figure description, we see that the Ptr-net is composed of an encoding RNN on one side, and a generating network on the other side, as opposed to using two RNNs for the sequence to sequence model.
The generating network of the Ptr-Net seems to output a softmax distribution over the inputs at each step, which is the so-called “pointer”.
After applying softmax on an input vector, each component of the resulting output vector of similar size, will be in the interval (0 , 1) and the components will add up to 1.
2. Insights from models:
In this section, we see a review of the sequence to sequence model, the input-attention model and finally the Ptr-Net model.
A/ Seq-to-seq model:
We assume the reader knows what RNNs are and how they are used to create a seq-to-seq model (if not, I would recommand reading this and/or this).
Authors define the probability of an output sequence of tokens, as the product of the conditional probability of the tokens that constitute our output given the tokens before them as well as the input sequence.
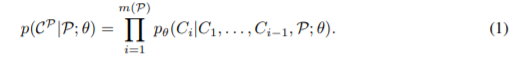
If our output Cp is made of 3 tokens, then we will have m(P)=3. The theta symbol represents the parameters of the model that is used to find this probability.
Here, the RNN that is used to generate the output sequence (the so-called decoder) models the conditional probabilities associated with the possible tokens, at each output time, given the tokens generated at previous output times.
During training, the model is trained to generate the proper output sequence, and the training set is used accordingly.
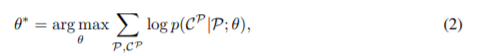
After training the model, we use it to find solutions to similar problems as the ones that are in the training set. This is the so-called inference process.
Main take-away:
The sequence to sequence model does not work when used on inputs of different size. There has to be one separate model for each input size “n”.
My best guess is that this is due to the size of the output being set upon initialization of the model.
More accurately, the decoding RNN generates hidden states at each output time. These hidden states are used in two ways:
- as an input for the RNN at the next step
- to calculate the output token at the current step
This second use of the hidden state is characterized by the dot product with a set of weights W(S) that converts the hidden state to a vector of fixed size, typically the size of the output dictionary.
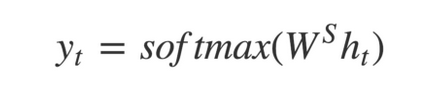
Because the size of W(S) is fixed upon initialization, it makes it impossible for the model to train on problems with different output dictionary sizes.
B/ Content based input attention:
The concept of attention is manifested in this paper with the formula:
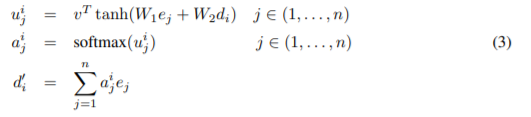
where e stands for encoder hidden states, d for decoder hidden states, W1, W2 and v are parameters of the attention network.
I am already familiar with the concept of attention from studying transformer based models such as BERT, which uses the “Scaled Dot-Product Attention” (you can read this article if you are interested: Masking in Transformers’ self-attention mechanism).
Although the attention mechanism here is not the same, the general purpose behind the use of attention is identical. The goal is to focus on subs-parts of the input sequence. To do that, authors concatenate a normalized distribution over the outputs or hidden states of the encoder to the hidden states of the decoder.
This stands in contrast with a regular sequence to sequence model, where the encoder only gives the last hidden state as input for the decoder.
Main take-away:
The attention mechanism allows to get better performances when compared with the regular sequence to sequence model. However, the problem of inputs of different size is not solved.
C/ Ptr-Net:
The idea behind Ptr-Net is actually quite simple. It uses the attention mechanism’s output to model the conditional probability of each token.
In other words, the step where the hidden state is multiplied by a set of weights W(S) is simply skipped.
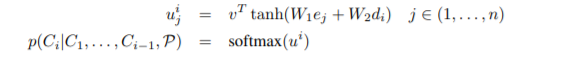
Main take-away:
The use of this model allows to train and infer on inputs of different size, while keeping good performance level.
…
The rest of the article shows how well the different models above perform on three different combinatorial problems.
Closing thoughts:
Scientific papers are a very good source of information, however, I’ve found from experience that sometimes they are a bit complicated. A great deal of information has to be transmitted through a limited amount of text. As a consequence, authors cannot explain everything, they assume that the reader has basic knowledge on the topic of interest.
Usually my preferred approach is to read articles on the web where the information is simplified, before reading the actual scientific paper. In this case, I could not find many other resources.
I hope that this short article helped you further your understanding on what pointer networks are.
